
You’ve undoubtedly encountered the term “machine learning” more than once . But do you know what it means and how it differs from artificial intelligence and deep learning? In this article, we’ll explain this idea in an easy-to-understand way and discuss how different machine learning training methods work
.
What is Machine Learning?
Machine Learning is a subset of Artificial Intelligence. As the name implies, it focuses on enabling machines—primarily computers—to learn specific tasks in a manner reminiscent of how humans learn.
This technology imparts knowledge to computers through data, observations, and interactions with their environment. Subsequently, they identify distinct patterns and insights. To achieve this, machine learning systems employ various algorithms, such as neural networks and clustering (check out: Glossary).
Crucially, machine learning algorithms hinge on a computer’s capability to discern pertinent patterns and correlations within the data automatically. They then make optimal decisions based on these insights.
What is the Difference Between Artificial Intelligence and Machine Learning?
Machine learning is often confused with artificial intelligence. But how do they differ? Let’s clarify this common misconception.
At its core, artificial intelligence (AI) is a broad discipline that encompasses creating machines capable of carrying out tasks that would traditionally require human intelligence, like understanding spoken language or identifying objects in images.
Machine learning, on the other hand, is a subset of artificial intelligence. It focuses explicitly on crafting algorithms and models that can learn and adapt from data and experience. Machine learning, on the other hand, is a subset of artificial intelligence.
Consider the relationship between fruits and apples to provide a more precise distinction. Think of artificial intelligence as the larger category of fruits. In this analogy, machine learning is like apples—a specific type within the broader category. All apples are fruits, but not every fruit is an apple. Similarly, all machine learning-based systems fall under the umbrella of artificial intelligence, but not every AI system is based on machine learning.
Additionally, it’s important to note that machine learning itself has subfields, such as deep learning. To better grasp this hierarchy, please refer to the illustration below:
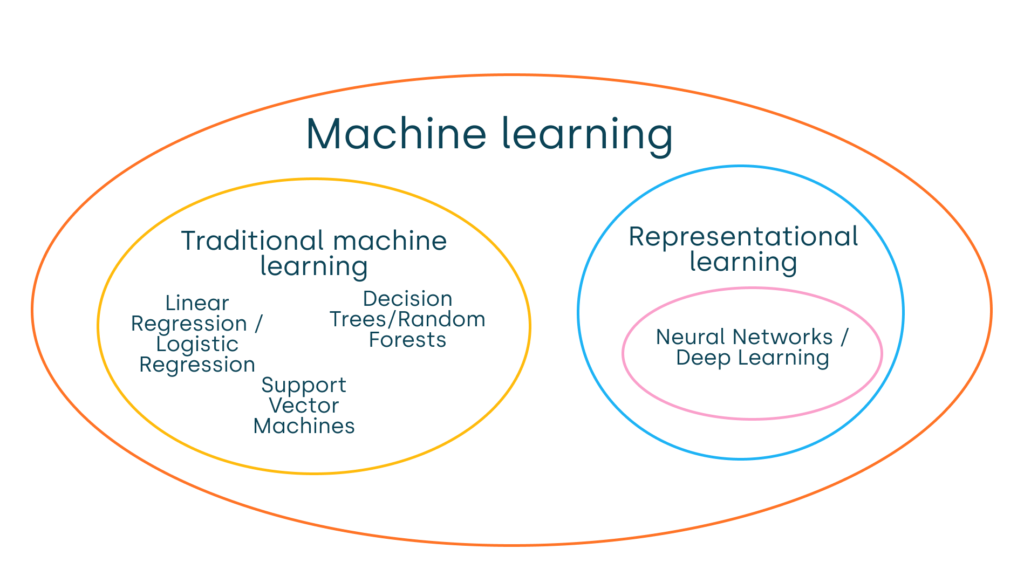
How does Machine Learning Work?
The process of machine learning consists of several basic steps that can be easily illustrated:
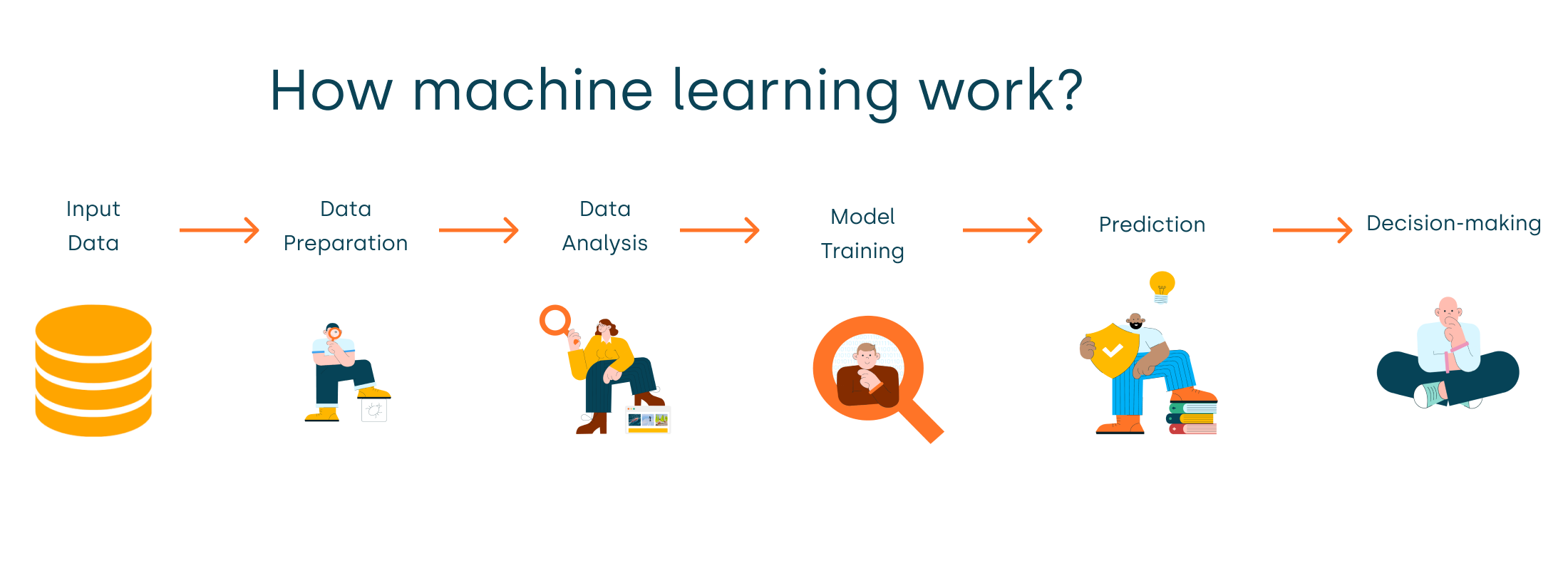
- Input Data: The journey begins with data collection, encompassing various forms like photos, texts, sounds, and numerical figures.
- Data Preparation: Once gathered, the data undergoes a cleaning process to ensure its accuracy. This phase involves rectifying inaccuracies, addressing errors, and filling in missing values. While this step is optional, it’s highly recommended to achieve superior outcomes.
- Data Analysis: At this juncture, the machine learning model delves into understanding the data’s structure and discerning relationships between its various features.
- Pattern Search: Leveraging insights from the analysis, the model unearths hidden patterns and connections within the data.
- Prediction: Drawing on these identified patterns, the model is primed to forecast outcomes for new, unseen data.
- Decision-making: Informed by the predictions, the system arrives at specific conclusions and takes corresponding actions. An example would be the system classifying an email as spam or legitimate; depending on this classification, it’ll then allocate the email to the relevant folder.
Machine Learning Techniques
The specifics of the machine learning process can vary based on the technique used. Below, we outline four fundamental methods.
Supervised Learning
Supervised learning is a technique where a model learns from input data and its corresponding output, provided with known labels (usually given by a human).
Take, for instance, a scenario where you aim to train a system to distinguish between an apple and a strawberry. Your training dataset would comprise images of the fruits (the input) and their respective identifications as an apple or a strawberry (the label). The system then processes this data, grasping the connection between the input and the output. As a result, it’s equipped to identify these fruits in future instances independently.
Common supervised learning applications encompass tasks like spam email detection and the fruit identification example mentioned earlier.
Within supervised learning lies regression, a technique aimed at predicting numerical values. It seeks to establish a relationship between one or multiple independent variables and a dependent variable.
For example, regression might be used to anticipate a company’s stock price or the selling price of items.
Unsupervised Learning
Unsupervised learning involves a model analyzing a set of input data without the aid of known labels.
Contrary to supervised learning, the algorithm isn’t equipped with predetermined answers here. It seeks to unearth hidden patterns and structures within the data and discern correlations.
Drawing from the fruit analogy, if the system receives a series of fruit images without any specific labeling, it can autonomously categorize them based on inherent similarities. However, it won’t inherently discern that one cluster represents apples and another signifies strawberries.
The core objective of unsupervised learning is to delve into data, unveiling latent patterns or structures. While it doesn’t necessitate “supervision” in the conventional understanding, the results might still warrant a human touch for interpretation.
Applications of unsupervised learning span areas like customer segment clustering, anomaly detection, and topic clustering for articles.
Semi-supervised Learning
Semi-supervised learning strikes a balance between supervised and unsupervised techniques. It leverages a mix of a limited amount of labeled data and a substantial volume of unlabeled data. The primary objective is to harness the labeled samples to interpret better the structure inherent in the larger, unlabeled dataset.
A significant advantage of this method is its ability to produce accurate models while drastically reducing the expenses and effort of data labeling. This positions semi-supervised learning as a valuable tool in scenarios where manual annotation proves costly or time-intensive, yet unlabeled data are abundant.
Practical applications of semi-supervised learning span domains like speech analysis, natural language processing, and fraud detection.
Reinforcement Learning
Reinforcement learning is a technique where a machine learns through interaction with its environment. Distinct from supervised learning, which provides the machine with explicit responses, reinforcement learning hinges on the principle of trial and error instead of relying on a specific dataset for training.
Within this paradigm, an agent (model or algorithm) carries out actions in a given environment, receiving rewards or penalties in return. The process centers on discerning which actions yield the highest reward under specific environmental conditions. Central to this approach is the “reward” – a quantitative measure of the system’s success in achieving its objectives.
Consider the challenge of teaching a robot to walk. Instead of supplying step-by-step instructions for each limb’s movement, the robot receives positive feedback or “rewards” for correct actions and “penalties” or negative feedback when it stumbles. . The robot refines its movements by consistently navigating this feedback to garner optimal outcomes.
Another illustrative example is mastering the game of chess. . Here, the model’s actions equate to the moves it makes, the environment corresponds to the game board and the rival’s plays, and the eventual reward hinges on whether the game is won or lost.
Reinforcement learning finds applications in diverse domains. Examples range from autonomous vehicles navigating impediments to trading algorithms making market moves to enhance gains or curtail losses. Additionally, games such as chess, Go, and Starcraft have been pivotal in advancing reinforcement learning. Interestingly, developing virtual assistants like ChatGPT also leans on reinforcement learning, among other methodologies.
Glossary of Key Terms Related to Machine Learning
- Neural Networks: Models inspired by the human brain’s structure, emphasizing pattern recognition. They are applied in language translation, image, and speech recognition.
- Deep Neural Networks: A specific subtype of neural networks with multiple layers between the input and output. Each layer consists of neurons that process data and relay it onward. More layers allow the model to discern intricate and abstract features in data.
- Linear Regression: An algorithm that predicts a continuous numerical value based on a linear combination of other variables. For example, it might estimate an apartment’s rental price considering factors like square footage, room count, and location.
- Logistic Regression: A model for categorical predictions, such as binary outcomes. It is commonly used in tasks like spam classification.
- Clustering: An algorithm that segments data into groups based on similarities, spotlighting patterns that might elude human observers.
- Decision Trees: isually represent decisions and potential outcomes in a tree-like format. Useful for both predicting values and classifying data. Their primary advantage lies in the straightforward interpretation and knowledge extraction from the model.
- Random Forests: An ensemble method integrating multiple decision trees to bolster prediction accuracy and counteract overfitting.
- Deep Learning: A machine learning subdomain that employs deep neural networks for intricate tasks. Owing to its profound depth and complexity, it excels at analyzing intricate patterns in extensive datasets, proving instrumental in advanced image recognition, natural language processing, and audio analysis.
Conclusion
It was the third edition of our series, delving into the pivotal concepts surrounding AI. If you’re yet to explore our pieces on artificial intelligence, Big Data, or neural networks, we strongly recommend you dive into those posts to consolidate your understanding.
If you have any inquiries about machine learning, don’t hesitate to contact us. 🙂